
1. Update Statistics
Accurate column/index statistics is one of the important parameter for sql server query optimizer to generate good performance execution plan. When you found some existing stored procs and sql batches ran good before but run slow now, the 1st thing you should do is to check whether your database has a statistics update schedule. If not, create it. Running statistics update doesn't imply any table locking, so if the users are daunting and your boss is yelling now, run the statistics update immediately. Be aware that the statistics sample size plays a critical role on its effectiveness, my practice is at least 10% sample size. You can execute sp_updatestats to let SQL Server update the statistics (sp_updatestats updates only the statistics that require updating based on the rowmodctr information in the sys.sysindexes, but even 1 row modified it will update too!) by using the default sampling. You can also use below statement to update statistics for each table on a database:
EXEC sp_MSforeachtable 'UPDATE STATISTICS ? WITH SAMPLE 10 PERCENT';
You can create an agent job for it, and schedule it to run per week/month. A better solution is provided: Update Statistics based on the Percentage of Modifications. You should also consider enabling AUTO_UPDATE_STATISTICS_ASYNC ON (which default was off) with AUTO_UPDATE_STATISTICS ON (default also on), especially if your application has experienced client request time outs caused by query waiting for synchronous auto update statistics. E.g.
ALTER DATABASE <UserDB> SET AUTO_UPDATE_STATISTICS_ASYNC ON;
SELECT name, is_auto_update_stats_on, is_auto_update_stats_async_on FROM sys.databases;
With synchronous auto-update statistics (AUTO_UPDATE_STATISTICS_ASYNC default OFF), when a query fires a sync. auto-update statistics, the auto-update statistics action is performed by the same sql process (spid) of the query, the query need to wait until auto-update statistics completed before re-compilation. If the query times out (e.g. ADO.NET default sql query timeout is 30secs), the update statistics action will be rolled-back. Later if the same query arrive again, it will still fire auto-update statistics, and highly possible to time out again. We can prevent such situation by setting AUTO_UPDATE_STATISTICS_ASYNC ON, it's because system spids (NOT the user spid) are used to perform the Asynchronous auto-update statistics operation and they are unaffected by the query timeout.
2. Index Defrag
Index fragmentation leads poor I/O performance. There's a free tools, Idera SQL Fragmentation Analyzer, which is a handy graphical tools to identify the fragmentation level of database tables and indexes.
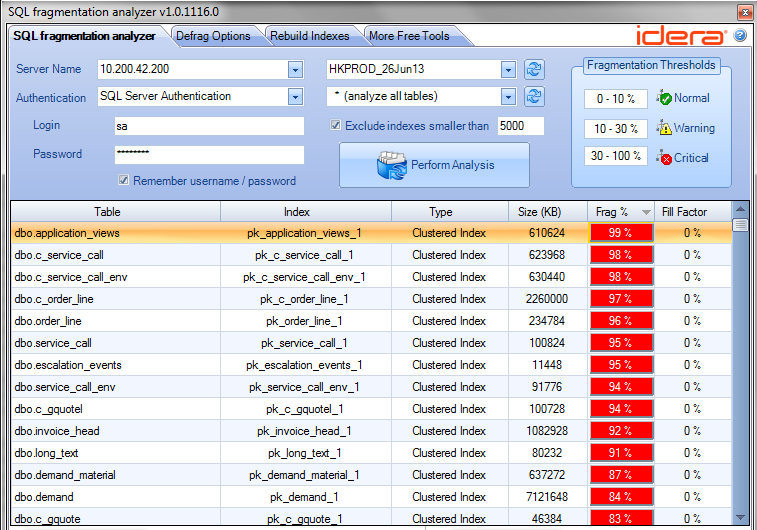
3. Real-time Performance Monitor
Most of the time a sql server running slow is not discovered by DBA, although a progressive DBA should implement some kind of alerts/reports on some significant performance counters. Most likely the issue is raised by users' complaints on the application running slower and slower. As a DBA, you should look at the big picture first, and then drill down to more details. There's a sql server performance monitoring freeware, Idera SQL Check, graphically presents the real-time system performance figures of sql server.

4. Missing Index
When there's no any suitable index available for sql server to execute a query, it falls into table scan. When the software system just launched, as there's not much data inside the database, users may not notice any slowness problem. But as the production database being populated day-to-day, query response getting slower and slower. There are two ways to obtain information of missing index, one is from missing index DMVs, another is from the execution plan. Below script can be used to obtain the top 25 missing indexes from the DMVs:
SELECT TOP 25
dm_mid.database_id AS DatabaseID,
dm_migs.avg_user_impact*(dm_migs.user_seeks+dm_migs.user_scans) Avg_Estimated_Impact,
dm_migs.last_user_seek AS Last_User_Seek,
object_name(dm_mid.object_id,dm_mid.database_id) AS [TableName],
'CREATE INDEX [IX_' + object_name(dm_mid.object_id,dm_mid.database_id) + '_'
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.equality_columns,''),', ','_'),'[',''),']','') +
CASE
WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN '_'
ELSE ''
END
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.inequality_columns,''),', ','_'),'[',''),']','')
+ ']'
+ ' ON ' + dm_mid.statement
+ ' (' + ISNULL (dm_mid.equality_columns,'')
+ CASE WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN ',' ELSE
'' END
+ ISNULL (dm_mid.inequality_columns, '')
+ ')'
+ ISNULL (' INCLUDE (' + dm_mid.included_columns + ')', '') AS Create_Statement
FROM sys.dm_db_missing_index_groups dm_mig
INNER JOIN sys.dm_db_missing_index_group_stats dm_migs
ON dm_migs.group_handle = dm_mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details dm_mid
ON dm_mig.index_handle = dm_mid.index_handle
WHERE dm_mid.database_ID = DB_ID()
ORDER BY Avg_Estimated_Impact DESC
GO
If you know which specific stored proc/sql batch running slow, you can also get the missing index from the Actual Execution Plan.

5. Execution Plan
Actual execution plan tells you the truth of what sql server really does to execute a query. A free execution plan viewer, SQL Sentry Plan Explorer, is a great tool to identity the most expensive operator inside an execution plan.

6. SQL Profiler + Qure Analyzer
SQL Profiler is a great tool to capture the performance of your stored procs and sql batches (remember that 'Logical Reads' might be misleading so pay close attention to both 'CPU' and 'Duration' when evaluating the queries’ true efficiency, referring to SQL Server Logical Reads – What do they really tell us?). By the way, it doesn't give you any summary. That's why you need another 3rd party freeware, DBSophic Qure Analyzer, which summarizes the trace captured by profiler. You can download the profiler trace templates for Qure Analyzer from its website, start a trace using that template, then input the trace result to Qure Analyzer to generate the workload summary.


7. Row Versioning-based Isolation Levels
This feature was firstly introduced in SQL 2005, which changes the locking scheme of data reading such as SELECT statement. By default, all databases newly created don't enable row-versioning, you should enable it manually. If you start a new project or migrate a database from SQL 2000, you can consider to enable it by running this statement:
ALTER DATABASE YourDB READ_COMMITTED_SNAPSHOT ON;
This little change on your database can greatly enhance the performance of your database. Reading operations no more acquire any shared locks, therefore do not block transactions that are modifying data. Also, the overhead of locking resources is minimized as the number of locks acquired is reduced. If the data being read is exclusively locked by an writing operation, those reading operations read the last committed snapshot of data from tempdb, where the snapshot was wrote by the writing operation using a mechanism called copy-on-write.
If you found your database has many blocked processes among reading and writing, then you must try READ_COMMITTED_SNAPSHOT. But before enabling it, you should make sure your tempdb has enough free disk space to growth.
8. Blocked Process & Deadlock
Blocked process and deadlock issues require experienced DBA who is proficient in SQL programming, with in-depth knowledge of transaction isolation and locking, in order to resolve these two difficult but common problems. Anyway, before fixing any problem, you must be notified that something occurred, and able to further investigate them. You need SQL Alerts to notify you, and record the blocking/deadlock events. Below two links are excellent approaches to do, again, it's free, and it's well tested (I used it for 2 years already, applied on all production databases that under my administration):
http://www.practicalsqldba.com/2012/07/sql-server-instant-blocking-alert-using.html
http://www.practicalsqldba.com/2012/07/sql-server-instant-deadlock-alert-using.html
Deadlock event can also be captured in sql server error log by enabling trace flag 1222: DBCC TRACEON(1222, -1)
Before these alerts can run, you must enable Database Mail. These alerts send email to notify DBA and record the blocking/deadlock events into tables which you can further investigate.
By the way, if your database has too much blocked processes (as you know, blocking always occur like a tree, one head blocker blocks multiple processes, and those blocked processes block another, and so on...) the above approach may generate too many alerts, too many emails, and increase server loading. So I developed another one as below:
SET NOCOUNT ON;
DECLARE @profile_name sysname, @recipients varchar(max), @subject nvarchar(255), @body nvarchar(max), @waittime bigint
-- Change Settings ---
-- **** DB MAIL PROFILE ****
SET @profile_name = 'AE_Sys_Mail'
-- **** EMAIL RECIPIENTS, semicolon-delimited ; ****
SET @recipients = 'peter.lee@jos.com.hk;'
-- **** Wait Time Threshold in milliseconds ****
SET @waittime = 1000--300000
SET @subject = 'Alert - DB Blocked Process (SQL Server: ' + @@SERVERNAME + ')'
SET @body = 'DB blocked process threshold (' + CAST(@waittime / 1000 AS varchar(50)) + ' seconds) exceed in SQL Server ' + @@SERVERNAME + '.
' +
'Below are the process information (1st row is the head blocker, followed by its top 10 waiting processes).
' +
'To see the full set, please execute stored procedure master.dbo.ViewProcessBlocking
'
IF EXISTS (SELECT 1 FROM master.sys.sysprocesses WHERE spid > 50 AND ISNULL(blocked, 0) <> 0 AND blocked <> spid AND waittime > @waittime)
BEGIN
-- ViewProcessBlockingLite SP result set
DECLARE @htmlTable varchar(max)
CREATE TABLE #t (SPID varchar(100), BlockingSPID varchar(100), DB varchar(100), BlockingObject varchar(100),
[Statement/Definition (first 100 chars)] varchar(100), program varchar(100), [login] varchar(100),
host varchar(100), login_time varchar(100), last_batch varchar(100), waittime_ms varchar(100), waitresource varchar(100))
INSERT #t EXEC ViewProcessBlockingLite
DECLARE @rowcount bigint
SELECT @rowcount = COUNT(*) FROM #t
IF @rowcount > 1
BEGIN
--Sending Mail
EXEC ConvertTableToHtml 'SELECT * FROM #t', @htmlTable OUTPUT
SET @body = @body + '
' + @htmlTable
EXEC msdb.dbo.sp_send_dbmail
@profile_name = @profile_name,
@recipients = @recipients,
@body = @body,
@body_format = 'HTML',
@subject = @subject,
@importance = 'Normal';
END
DROP TABLE #t
END
This is the body of a sql agent job, which should be scheduled to run periodically, let's say per one minute. This alert will only send one email to you when a blocking event occured, rather than send one email per each blocked processes.
9. Long Running Query
Some queries run slow without any reason but only because they're not fast enough. You can find the top 50 long running queries from the following query:
SELECT TOP 50
DB_NAME(qt.dbid) AS [Database],
OBJECT_NAME(qt.objectid, qt.dbid) AS [Object],
LEFT(qt.[text], 255) AS [text],
Query = SUBSTRING(qt.[text], (qs.statement_start_offset / 2) + 1,
(
(
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.[text])
ELSE qs.statement_end_offset
END - qs.statement_start_offset
) / 2
) + 1
),
creation_time AS [plan cache create time],
[Avg. Elapsed Time(sec)] = qs.total_elapsed_time / 1000000 / qs.execution_count,
[Total Elapsed Time(sec)] = qs.total_elapsed_time / 1000000,
qs.execution_count,
qs.last_execution_time,
[Last Elapsed Time(sec)] = qs.last_elapsed_time / 1000000
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.[sql_handle]) AS qt
--WHERE qs.execution_count > 5 --more than 5 occurences
ORDER BY [Avg. Elapsed Time(sec)] DESC
10. Parameter Sniffing
Microsoft has its official explanation on how query optimizer compiles stored procedures into execution plans (according to the column statistics, and the input parameters' values it sniffed, during compilation time). Sometimes you may find a SQL statement runs slow inside a stored proc, but it runs fast as an adhoc statement. The first option you should try is execute the stored proc with a RECOMPILE execution option, and compare the actual execution plans before and after that. If it improves the SQL statement's execution plan, then you can add a RECOMPILE query hints to that SQL statement inside the stored proc. Another option you can try is to wrap the input parameters being used by that SQL statement by local variables inside the stored proc. The purpose of the above two options are to bypass parameter sniffing, even Microsoft claims that it's a good feature for performance, but sometimes you just find it makes the query optimizer chooses the wrong execution plan.
11. Performance Monitor (perfmon.exe)
In order to capture SQL Server specific perfmon counters, you can use the following:
| Processor: % Processor Time | Should average below 75% (and preferably below 50%). |
|---|---|
| System: Processor Queue Length | Should average below 2 per processor. For example, in a 2-processor machine, it should remain below 4. |
| Memory—Pages/sec | Should average below 20 (and preferably below 15). |
| Memory—Available Bytes | Should remain above 50 MB. |
| Physical Disk—% Disk Time | Should average below 50%. |
| Physical Disk—Avg. Disk Queue Length | Should average below 2 per disk. For example, for an array of 5 disks, this figure should average below 10. |
| Physical Disk—Avg. Disk Reads/sec | Used to size the disk and CPU. Should be below 85% of the capacity of the drive. |
| Physical Disk—Avg. Disk Writes/sec | Used to size the disk and CPU. Should be below 85% of the capacity of the drive. |
| Network Interface—Bytes Total/sec | Used to size the network bandwidth. |
| SQL Server: Buffer Manager— Buffer Cache Hit Ratio | Should exceed 90% (and ideally approach 99%). |
| SQL Server: Buffer Manager—Page Life Expectancy | Used to size memory. Should remain above 300 seconds. |
| SQL Server: General Statistics— User Connections | Used to size memory. |
| SQL Server: Databases— Transactions/sec | Used to size disks and CPU. |
| SQL Server: Databases—Data File(s) Size KB | Used to size the disk subsystem. |
| SQL Server: Databases—Percent Log | Used to size the disk subsystem. |
12. Follows SQL Coding Practices
SQL coding does matter on performance. Here're some tips on SQL coding:
SQL Coding Practices
Hope you find this information useful.
No comments:
Post a Comment