
- only support Non-Clustered ColumnStore Indexes
- table had created a ColumnStore Index becomes READ ONLY table
However, SQL Server 2014 provides you an Updateable Clustered ColumnStore Index! Let’s have a more detailed look on how this magic and illusion happens internally in SQL Server.
The first most important fact is that an underlying direct update of a ColumnStore Index is not possible! It would be too time consuming to do the complete decompress and compress on the fly during your INSERT, UPDATE, and DELETE transactions. Therefore SQL Server 2014 uses help from some magic: Delta Stores and Delete Bitmaps.
Every time when you run an INSERT statement, the new record isn’t directly inserted into the ColumnStore Index – the record is inserted into a Delta Store. The Delta Store itself is nothing else than a traditional B-Tree structure with all its pro’s and con’s. When you afterwards read from the ColumnStore Index, SQL Server returns you the data from the compressed ColumnStore Index AND also from the Delta Store.
When you run an DELETE statement, again nothing happens in the compressed ColumnStore Index. The only thing that happens is that the record is deleted logically through a Delete Bitmap. Every record in the ColumnStore Index has a corresponding bit in that Delete Bitmap. When you again read your ColumnStore Index, SQL Server just discards the rows that are marked as deleted in the Delete Bitmap.
And running an UPDATE statement just means inserting the new version into the Delta Store, and marking the old version as deleted in the Delete Bitmap.
The following picture (source http://research.microsoft.com/apps/pubs/default.aspx?id=193599) shows this concept.
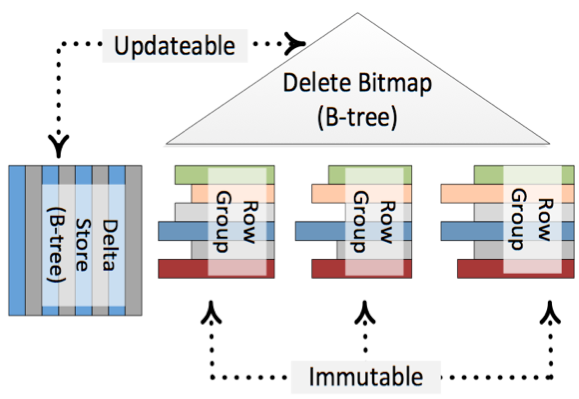
Because of the Delta Stores and the Delete Bitmap it seems that your ColumnStore Index is updateable, but in reality it is just immutable. There is also a background process called the Tuple Mover, which runs regularly and finally pushes your changes asynchronously into the compressed ColumnStore Index.
According to BOL, row groups in deltastore can be in one of 3 possible statuses: OPEN (a read/write row group that is accepting new records. An open row group is still in rowstore format and has not been compressed to columnstore format), CLOSED (a row group that has been filled, but not yet compressed by the tuple mover process) and COMPRESSED (a row group that has filled and compressed). COMPRESSED actually means that data is already part of the index. Row groups that are still in OPEN or CLOSED state are yet to be added to the index and currently reside somewhere in deltastore.
Anyway, performance difference between fully updated columnstore index and situation when part of your data that is still in OPEN or CLOSED state in deltastore is huge. So we would like the background process that indexes and compresses data to be as fast as possible. Unfortunately it is painfully slow.
Suppose you loaded billions of rows into a clustered columnstore index. When loading had finished, actually the clustered columnstore index is NOT ready yet, many rows are still in deltastore, waiting for the tuple mover to compress them. During this transition state, if you run a query on this table, it scans the entire deltastore. It's because there is no traditional b-tree index on the data in deltastore, and columnstore index isn’t ready yet. Even if required data resides fully inside columnstore index, SQL Server cannot be sure about that, so scan is inevitable.
What does it mean? It means that updateable clustered/nonclustered columnstore indexes should be used with extreme caution. If your data is constantly updated (loaded) or if you have huge single ETL but not enough time for a background process to calculate entire index before users start to query it – result can be extremely painful.