In SQL Server 2012, there's a new way to do row pagination, using the new keywords OFFSET and FETCH NEXT. The example below demonstrates how to show the 3rd page (OFFSET 20 ROWS) of the vEmployee view, 10 rows per page, ordered by BusinessEntityID:
SELECT *
FROM HumanResources.vEmployee
ORDER BY BusinessEntityID
OFFSET 20 ROWS
FETCH NEXT 10 ROWS ONLY
Be aware that the OFFSET keyword must be used with ORDER BY, and FETCH NEXT must be used with OFFSET. So if you need the 1st page, just set OFFSET 0 ROWS.

SQL Server Technical Blog by a Microsoft Certified Professional in SQL Server - LEE HongLeung, Peter
2014-11-16
2014-11-11
How to identify a suboptimal execution plan
You can check the execution plan of a query by two ways. The first way is displaying the estimated execution plan, which the T-SQL queries do not execute, it just shows you an estimation which may not be accurate (that's why I seldom use it). If you want to know how good is your query really performs, you must execute the queries with Include Actual Execution Plan turns on.

Many people think that the "Query cost (relative to the batch)" can be used to check which is the most expensive query in a batch. No, it's not the truth, the "Query cost (relative to the batch)" is based on estimated cost, not on actual cost (reference: “Query cost (relative to the batch)” NOT equals to Query cost relative to batch). You must use SQL Profiler to check the "Duration" and "CPU" columns in order to check the actual cost.

After you identity an expensive query in the batch by checking the Duration and CPU of it in SQL Profiler, you can go back to the graphical Acutal Execution Plan in SSMS. Mouse hover any "thick" arrows (the thickness reflects the Actual Number of Rows affected by an operator), you will see the "Actual Number of Rows" and "Estimated Number of Rows", and if these two figures are very far away, then it's the evidence that the SQL Server optimizer didn't make a good enough estimation. You should check whether the statistics are updated, any indexes can be added to help, rewriting the SQL, or even forcing it by using query hints as a last resort.


Many people think that the "Query cost (relative to the batch)" can be used to check which is the most expensive query in a batch. No, it's not the truth, the "Query cost (relative to the batch)" is based on estimated cost, not on actual cost (reference: “Query cost (relative to the batch)” NOT equals to Query cost relative to batch). You must use SQL Profiler to check the "Duration" and "CPU" columns in order to check the actual cost.

After you identity an expensive query in the batch by checking the Duration and CPU of it in SQL Profiler, you can go back to the graphical Acutal Execution Plan in SSMS. Mouse hover any "thick" arrows (the thickness reflects the Actual Number of Rows affected by an operator), you will see the "Actual Number of Rows" and "Estimated Number of Rows", and if these two figures are very far away, then it's the evidence that the SQL Server optimizer didn't make a good enough estimation. You should check whether the statistics are updated, any indexes can be added to help, rewriting the SQL, or even forcing it by using query hints as a last resort.

2014-11-03
Implement Excel style Rolling Calulation by T-SQL
Excel is a great tool to implement financial calculations, especially rolling calculation, which the value of a column in a row is based on the value of previous rows. E.g.

Such calculation can also be implemented in SQL Server, but many developers may do it by using CURSOR, which is not a effective way, if the number or rows is huge, then the processing time can be very long.
Below is the sample code of an effective implementation by using CROSS APPLY in T-SQL:
DECLARE @nonno TABLE (eDate date NOT NULL, result float NULL, perf float NULL)
INSERT @nonno (eDate, result, perf)
VALUES('20100104', 21823.28, NULL),
('20100105', NULL, 0.00485),
('20100106', NULL, 0.01846),
('20100107', NULL, 0.00129),
('20100108', NULL, 0.01022)
UPDATE @nonno
SET result = COALESCE(t1.result * t1.perf * (1 + t.perf),t.result)
FROM @nonno AS t
CROSS APPLY (SELECT MAX(result) AS result,EXP(SUM(LOG((1+COALESCE(perf,0))))) AS perf
FROM @nonno
WHERE eDate < t.eDate
)t1
SELECT [eDate],[result],[perf] FROM @nonno

Such calculation can also be implemented in SQL Server, but many developers may do it by using CURSOR, which is not a effective way, if the number or rows is huge, then the processing time can be very long.
Below is the sample code of an effective implementation by using CROSS APPLY in T-SQL:
DECLARE @nonno TABLE (eDate date NOT NULL, result float NULL, perf float NULL)
INSERT @nonno (eDate, result, perf)
VALUES('20100104', 21823.28, NULL),
('20100105', NULL, 0.00485),
('20100106', NULL, 0.01846),
('20100107', NULL, 0.00129),
('20100108', NULL, 0.01022)
UPDATE @nonno
SET result = COALESCE(t1.result * t1.perf * (1 + t.perf),t.result)
FROM @nonno AS t
CROSS APPLY (SELECT MAX(result) AS result,EXP(SUM(LOG((1+COALESCE(perf,0))))) AS perf
FROM @nonno
WHERE eDate < t.eDate
)t1
SELECT [eDate],[result],[perf] FROM @nonno
2014-10-06
Monitor Blocked Process and Deadlock using Extended Events
Using the free "Idera SQL Check" is great for real-time monitoring your SQL Server, but a historical log is much more important for you to investigate the performance problem. The Extended Events feature in SQL Server 2012 can be used to fulfill this need.
-- Blocked Process monitor --
sp_configure 'show advanced options', 1 ;
GO
RECONFIGURE ;
GO
sp_configure 'blocked process threshold', 10 ;
GO
RECONFIGURE ;
GO
CREATE EVENT SESSION [blockingMonitor] ON SERVER
ADD EVENT sqlserver.blocked_process_report(
ACTION(sqlos.task_time,sqlserver.database_id,sqlserver.database_name,sqlserver.request_id,sqlserver.sql_text))
ADD TARGET package0.event_file(SET filename=N'C:\Guosen\SqlMonitor\blockingMonitor.xel')
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=ON,STARTUP_STATE=OFF)
GO
ALTER EVENT SESSION [blockingMonitor] ON SERVER STATE=START
GO
-- Deadlock monitor --
CREATE EVENT SESSION [Deadlock_Graph] ON SERVER
ADD EVENT sqlserver.xml_deadlock_report
ADD TARGET package0.event_file(SET filename=N'C:\Guosen\SqlMonitor\Deadlock_Graph.xel',max_file_size=(100),max_rollover_files=(10))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO
Then you can check the log in SSMS illustrated as below.

-- Blocked Process monitor --
sp_configure 'show advanced options', 1 ;
GO
RECONFIGURE ;
GO
sp_configure 'blocked process threshold', 10 ;
GO
RECONFIGURE ;
GO
CREATE EVENT SESSION [blockingMonitor] ON SERVER
ADD EVENT sqlserver.blocked_process_report(
ACTION(sqlos.task_time,sqlserver.database_id,sqlserver.database_name,sqlserver.request_id,sqlserver.sql_text))
ADD TARGET package0.event_file(SET filename=N'C:\Guosen\SqlMonitor\blockingMonitor.xel')
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=ON,STARTUP_STATE=OFF)
GO
ALTER EVENT SESSION [blockingMonitor] ON SERVER STATE=START
GO
-- Deadlock monitor --
CREATE EVENT SESSION [Deadlock_Graph] ON SERVER
ADD EVENT sqlserver.xml_deadlock_report
ADD TARGET package0.event_file(SET filename=N'C:\Guosen\SqlMonitor\Deadlock_Graph.xel',max_file_size=(100),max_rollover_files=(10))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO
Then you can check the log in SSMS illustrated as below.

Get the permissions, roles, and default schema of database user
You can check the granted permissions, roles, and default schema of an database user by using the SSMS GUI. By the way, by using Transact-SQL, you can get these information quickly for all database users one shot.
/* List all permissions on database users & roles */
SELECT
princ.name,
princ.type_desc,
perm.[permission_name],
perm.state_desc,
perm.class_desc,
OBJECT_NAME(perm.major_id) AS [object]
FROM sys.database_principals princ
LEFT JOIN sys.database_permissions perm
ON perm.grantee_principal_id = princ.principal_id
ORDER BY princ.type_desc, princ.name, [object], perm.[permission_name]
/* List all users and associated roles */
SELECT rp.name AS database_role, mp.name AS database_user
FROM sys.database_role_members AS drm
JOIN sys.database_principals rp ON drm.role_principal_id = rp.principal_id
JOIN sys.database_principals mp ON drm.member_principal_id = mp.principal_id
ORDER BY database_role, database_user
/* List default schema of each user */
SELECT default_schema_name,
type_desc,
name,
create_date
FROM sys.database_principals
ORDER BY default_schema_name, type_desc, name
/* List all permissions on database users & roles */
SELECT
princ.name,
princ.type_desc,
perm.[permission_name],
perm.state_desc,
perm.class_desc,
OBJECT_NAME(perm.major_id) AS [object]
FROM sys.database_principals princ
LEFT JOIN sys.database_permissions perm
ON perm.grantee_principal_id = princ.principal_id
ORDER BY princ.type_desc, princ.name, [object], perm.[permission_name]
/* List all users and associated roles */
SELECT rp.name AS database_role, mp.name AS database_user
FROM sys.database_role_members AS drm
JOIN sys.database_principals rp ON drm.role_principal_id = rp.principal_id
JOIN sys.database_principals mp ON drm.member_principal_id = mp.principal_id
ORDER BY database_role, database_user
/* List default schema of each user */
SELECT default_schema_name,
type_desc,
name,
create_date
FROM sys.database_principals
ORDER BY default_schema_name, type_desc, name
Check the DB size and table size in SQL Azure
Calculating the database size is very important, especially for a SQL Azure database, as it determines the editions you can choose and how much money you need to pay.
System stored procedure sp_spaceused is unavailable in SQL Azure. But you can still check the DB size and table size by running the following SQL statements:
select sum(reserved_page_count) * 8.0 / 1024 AS [DB size MB] from sys.dm_db_partition_stats
select sys.objects.name, sum(reserved_page_count) * 8.0 / 1024 AS [size MB]
from sys.dm_db_partition_stats, sys.objects
where sys.dm_db_partition_stats.object_id = sys.objects.object_id
--and sys.objects.type = 'U'
group by sys.objects.name
ORDER BY [size MB] DESC
By filtering the results where sys.objects.type = 'U', you can get the user tables only; otherwise system tables will be included.
System stored procedure sp_spaceused is unavailable in SQL Azure. But you can still check the DB size and table size by running the following SQL statements:
select sum(reserved_page_count) * 8.0 / 1024 AS [DB size MB] from sys.dm_db_partition_stats
select sys.objects.name, sum(reserved_page_count) * 8.0 / 1024 AS [size MB]
from sys.dm_db_partition_stats, sys.objects
where sys.dm_db_partition_stats.object_id = sys.objects.object_id
--and sys.objects.type = 'U'
group by sys.objects.name
ORDER BY [size MB] DESC
By filtering the results where sys.objects.type = 'U', you can get the user tables only; otherwise system tables will be included.
2014-07-29
Difference of Isolation Levels between Azure SQL DB and on-premise SQL Server DB
By default, when you create a new database on an on-premise SQL Server, the database options of isolation level, READ_COMMITTED_SNAPSHOT and ALLOW_SNAPSHOT_ISOLATION, should be turned OFF (default settings in the model database). But in Azure SQL DB, both of them are turned ON and can't be turned off (ref.: http://msdn.microsoft.com/en-us/library/ee336245.aspx#isolevels). You can check the difference by running the following statement:
SELECT name, snapshot_isolation_state, is_read_committed_snapshot_on FROM sys.databases
So, if you migrate your database from on-premise SQL Server to Azure SQL, make sure your program code doesn't depend on Shared Locks to maintain data integrity.
SELECT name, snapshot_isolation_state, is_read_committed_snapshot_on FROM sys.databases
So, if you migrate your database from on-premise SQL Server to Azure SQL, make sure your program code doesn't depend on Shared Locks to maintain data integrity.
2014-06-16
Caution in Updateable ColumnStore Index in SQL Server 2014
The introduction of ColumnStore Indexes in SQL Server 2012 was one of the hottest new features. A columnstore index stores data in a column-wise (columnar) format, unlike the traditional B-tree structures used for rowstore indexes, which store data row-wise (in rows). This structure can offer significant performance gains for queries that summarize large quantities of data, the sort typically used for business intelligence (BI) and data warehousing. Unfortunately, they had 2 big limitations:
- only support Non-Clustered ColumnStore Indexes
- table had created a ColumnStore Index becomes READ ONLY table
However, SQL Server 2014 provides you an Updateable Clustered ColumnStore Index! Let’s have a more detailed look on how this magic and illusion happens internally in SQL Server.
The first most important fact is that an underlying direct update of a ColumnStore Index is not possible! It would be too time consuming to do the complete decompress and compress on the fly during your INSERT, UPDATE, and DELETE transactions. Therefore SQL Server 2014 uses help from some magic: Delta Stores and Delete Bitmaps.
Every time when you run an INSERT statement, the new record isn’t directly inserted into the ColumnStore Index – the record is inserted into a Delta Store. The Delta Store itself is nothing else than a traditional B-Tree structure with all its pro’s and con’s. When you afterwards read from the ColumnStore Index, SQL Server returns you the data from the compressed ColumnStore Index AND also from the Delta Store.
When you run an DELETE statement, again nothing happens in the compressed ColumnStore Index. The only thing that happens is that the record is deleted logically through a Delete Bitmap. Every record in the ColumnStore Index has a corresponding bit in that Delete Bitmap. When you again read your ColumnStore Index, SQL Server just discards the rows that are marked as deleted in the Delete Bitmap.
And running an UPDATE statement just means inserting the new version into the Delta Store, and marking the old version as deleted in the Delete Bitmap.
The following picture (source http://research.microsoft.com/apps/pubs/default.aspx?id=193599) shows this concept.
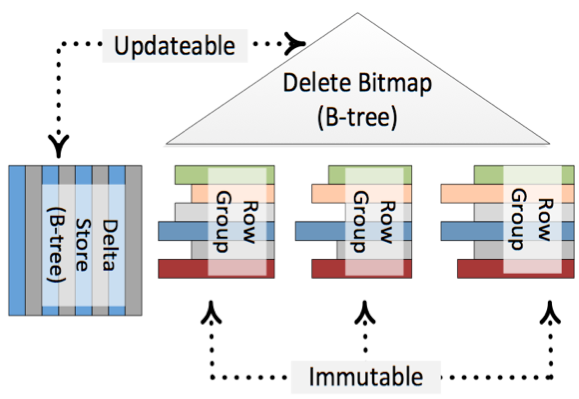
Because of the Delta Stores and the Delete Bitmap it seems that your ColumnStore Index is updateable, but in reality it is just immutable. There is also a background process called the Tuple Mover, which runs regularly and finally pushes your changes asynchronously into the compressed ColumnStore Index.
According to BOL, row groups in deltastore can be in one of 3 possible statuses: OPEN (a read/write row group that is accepting new records. An open row group is still in rowstore format and has not been compressed to columnstore format), CLOSED (a row group that has been filled, but not yet compressed by the tuple mover process) and COMPRESSED (a row group that has filled and compressed). COMPRESSED actually means that data is already part of the index. Row groups that are still in OPEN or CLOSED state are yet to be added to the index and currently reside somewhere in deltastore.
Anyway, performance difference between fully updated columnstore index and situation when part of your data that is still in OPEN or CLOSED state in deltastore is huge. So we would like the background process that indexes and compresses data to be as fast as possible. Unfortunately it is painfully slow.
Suppose you loaded billions of rows into a clustered columnstore index. When loading had finished, actually the clustered columnstore index is NOT ready yet, many rows are still in deltastore, waiting for the tuple mover to compress them. During this transition state, if you run a query on this table, it scans the entire deltastore. It's because there is no traditional b-tree index on the data in deltastore, and columnstore index isn’t ready yet. Even if required data resides fully inside columnstore index, SQL Server cannot be sure about that, so scan is inevitable.
What does it mean? It means that updateable clustered/nonclustered columnstore indexes should be used with extreme caution. If your data is constantly updated (loaded) or if you have huge single ETL but not enough time for a background process to calculate entire index before users start to query it – result can be extremely painful.
- only support Non-Clustered ColumnStore Indexes
- table had created a ColumnStore Index becomes READ ONLY table
However, SQL Server 2014 provides you an Updateable Clustered ColumnStore Index! Let’s have a more detailed look on how this magic and illusion happens internally in SQL Server.
The first most important fact is that an underlying direct update of a ColumnStore Index is not possible! It would be too time consuming to do the complete decompress and compress on the fly during your INSERT, UPDATE, and DELETE transactions. Therefore SQL Server 2014 uses help from some magic: Delta Stores and Delete Bitmaps.
Every time when you run an INSERT statement, the new record isn’t directly inserted into the ColumnStore Index – the record is inserted into a Delta Store. The Delta Store itself is nothing else than a traditional B-Tree structure with all its pro’s and con’s. When you afterwards read from the ColumnStore Index, SQL Server returns you the data from the compressed ColumnStore Index AND also from the Delta Store.
When you run an DELETE statement, again nothing happens in the compressed ColumnStore Index. The only thing that happens is that the record is deleted logically through a Delete Bitmap. Every record in the ColumnStore Index has a corresponding bit in that Delete Bitmap. When you again read your ColumnStore Index, SQL Server just discards the rows that are marked as deleted in the Delete Bitmap.
And running an UPDATE statement just means inserting the new version into the Delta Store, and marking the old version as deleted in the Delete Bitmap.
The following picture (source http://research.microsoft.com/apps/pubs/default.aspx?id=193599) shows this concept.
Because of the Delta Stores and the Delete Bitmap it seems that your ColumnStore Index is updateable, but in reality it is just immutable. There is also a background process called the Tuple Mover, which runs regularly and finally pushes your changes asynchronously into the compressed ColumnStore Index.
According to BOL, row groups in deltastore can be in one of 3 possible statuses: OPEN (a read/write row group that is accepting new records. An open row group is still in rowstore format and has not been compressed to columnstore format), CLOSED (a row group that has been filled, but not yet compressed by the tuple mover process) and COMPRESSED (a row group that has filled and compressed). COMPRESSED actually means that data is already part of the index. Row groups that are still in OPEN or CLOSED state are yet to be added to the index and currently reside somewhere in deltastore.
Anyway, performance difference between fully updated columnstore index and situation when part of your data that is still in OPEN or CLOSED state in deltastore is huge. So we would like the background process that indexes and compresses data to be as fast as possible. Unfortunately it is painfully slow.
Suppose you loaded billions of rows into a clustered columnstore index. When loading had finished, actually the clustered columnstore index is NOT ready yet, many rows are still in deltastore, waiting for the tuple mover to compress them. During this transition state, if you run a query on this table, it scans the entire deltastore. It's because there is no traditional b-tree index on the data in deltastore, and columnstore index isn’t ready yet. Even if required data resides fully inside columnstore index, SQL Server cannot be sure about that, so scan is inevitable.
What does it mean? It means that updateable clustered/nonclustered columnstore indexes should be used with extreme caution. If your data is constantly updated (loaded) or if you have huge single ETL but not enough time for a background process to calculate entire index before users start to query it – result can be extremely painful.
2014-05-12
SQL Agent Job Checker
Below SQL script is the body content of a sql agent job which sends email of failed agent jobs since yesterday:
SET NOCOUNT ON;
DECLARE @Value [varchar] (2048)
,@JobName [varchar] (2048)
,@PreviousDate [datetime]
,@Year [varchar] (4)
,@Month [varchar] (2)
,@MonthPre [varchar] (2)
,@Day [varchar] (2)
,@DayPre [varchar] (2)
,@FinalDate [int]
-- Declaring Table variable
DECLARE @FailedJobs TABLE ([JobName] [varchar](200))
-- Initialize Variables
SET @PreviousDate = DATEADD(dd, - 1, GETDATE())
SET @Year = DATEPART(yyyy, @PreviousDate)
SELECT @MonthPre = CONVERT([varchar](2), DATEPART(mm, @PreviousDate))
SELECT @Month = RIGHT(CONVERT([varchar], (@MonthPre + 1000000000)), 2)
SELECT @DayPre = CONVERT([varchar](2), DATEPART(dd, @PreviousDate))
SELECT @Day = RIGHT(CONVERT([varchar], (@DayPre + 1000000000)), 2)
SET @FinalDate = CAST(@Year + @Month + @Day AS [int])
-- Final Logic
INSERT INTO @FailedJobs
SELECT DISTINCT j.[name]
FROM [msdb].[dbo].[sysjobhistory] h
INNER JOIN [msdb].[dbo].[sysjobs] j
ON h.[job_id] = j.[job_id]
INNER JOIN [msdb].[dbo].[sysjobsteps] s
ON j.[job_id] = s.[job_id]
AND h.[step_id] = s.[step_id]
WHERE h.[run_status] = 0
AND h.[run_date] > @FinalDate
SELECT @JobName = COALESCE(@JobName + ', ', '') + '[' + [JobName] + ']'
FROM @FailedJobs
SELECT @Value = 'Failed SQL Agent job(s) found: ' + @JobName + '. '
IF @Value IS NULL
BEGIN
SET @Value = 'None.'
END
DECLARE @recipients varchar(max) = '<you and other DBA>'
DECLARE @subject nvarchar(255) = @@SERVERNAME + ' SQL Agent Job Failed since yesterday'
DECLARE @body nvarchar(MAX) = @Value
EXEC msdb.dbo.sp_send_dbmail @recipients = @recipients, @subject = @subject, @body_format = 'html', @body = @body;
SET NOCOUNT ON;
DECLARE @Value [varchar] (2048)
,@JobName [varchar] (2048)
,@PreviousDate [datetime]
,@Year [varchar] (4)
,@Month [varchar] (2)
,@MonthPre [varchar] (2)
,@Day [varchar] (2)
,@DayPre [varchar] (2)
,@FinalDate [int]
-- Declaring Table variable
DECLARE @FailedJobs TABLE ([JobName] [varchar](200))
-- Initialize Variables
SET @PreviousDate = DATEADD(dd, - 1, GETDATE())
SET @Year = DATEPART(yyyy, @PreviousDate)
SELECT @MonthPre = CONVERT([varchar](2), DATEPART(mm, @PreviousDate))
SELECT @Month = RIGHT(CONVERT([varchar], (@MonthPre + 1000000000)), 2)
SELECT @DayPre = CONVERT([varchar](2), DATEPART(dd, @PreviousDate))
SELECT @Day = RIGHT(CONVERT([varchar], (@DayPre + 1000000000)), 2)
SET @FinalDate = CAST(@Year + @Month + @Day AS [int])
-- Final Logic
INSERT INTO @FailedJobs
SELECT DISTINCT j.[name]
FROM [msdb].[dbo].[sysjobhistory] h
INNER JOIN [msdb].[dbo].[sysjobs] j
ON h.[job_id] = j.[job_id]
INNER JOIN [msdb].[dbo].[sysjobsteps] s
ON j.[job_id] = s.[job_id]
AND h.[step_id] = s.[step_id]
WHERE h.[run_status] = 0
AND h.[run_date] > @FinalDate
SELECT @JobName = COALESCE(@JobName + ', ', '') + '[' + [JobName] + ']'
FROM @FailedJobs
SELECT @Value = 'Failed SQL Agent job(s) found: ' + @JobName + '. '
IF @Value IS NULL
BEGIN
SET @Value = 'None.'
END
DECLARE @recipients varchar(max) = '<you and other DBA>'
DECLARE @subject nvarchar(255) = @@SERVERNAME + ' SQL Agent Job Failed since yesterday'
DECLARE @body nvarchar(MAX) = @Value
EXEC msdb.dbo.sp_send_dbmail @recipients = @recipients, @subject = @subject, @body_format = 'html', @body = @body;
2014-03-27
The right way to do case insensitive string comparison
If you have a case-sensitive database, and you need to do case insensitive string comparison on a table column, you may think using LOWER() or UPPER() function to convert that column value. Don't bother to do this, because it makes your code clumsy, also you will get slow performance as the conversion function hinders SQL Server query engine to use any index on that column. If you are sure that column is case insensitive, you should specify the collation of that column, that's all you need to do simple and clean. E.g.
CREATE TABLE [dbo].[Keyword](
[id] [int] IDENTITY(1,1) NOT NULL,
[keyword] [nvarchar](400) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[lastModifiedTime] [datetime] NOT NULL)
CREATE TABLE [dbo].[Keyword](
[id] [int] IDENTITY(1,1) NOT NULL,
[keyword] [nvarchar](400) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[lastModifiedTime] [datetime] NOT NULL)
2014-03-25
Creating C# client program for SQL Server 2012 FILETABLE
FILETABLE is a great new feature on SQL Server 2012, it automatically creates the table schema and maintain the relational and file data integrity for you. However, writing client application program code to access the FILETABLE is not as simple as creating a FILETABLE in sql server. The sample code below demonstrates how to write the client program in C#.
public static byte[] ReadAnalystReportPDF(string pathName)
{
byte[] buffer = new byte[0];
if (CommonUtil.IsEmpty(pathName)) return buffer;
string connStr = ConfigurationManager.ConnectionStrings["archiveDbConnectionString"].ConnectionString;
using (SqlConnection conn = new SqlConnection(connStr))
{
conn.Open();
SqlTransaction transaction = conn.BeginTransaction();
SqlCommand cmd = conn.CreateCommand();
cmd.Transaction = transaction;
cmd.CommandText = "SELECT GET_FILESTREAM_TRANSACTION_CONTEXT()";
Object obj = cmd.ExecuteScalar();
byte[] txContext = (byte[])obj;
SqlFileStream fileStream = new SqlFileStream(pathName, txContext, FileAccess.Read);
buffer = new byte[(int)fileStream.Length];
fileStream.Read(buffer, 0, buffer.Length);
fileStream.Close();
cmd.Transaction.Commit();
}
return buffer;
}
public static void UploadAnalystReportPDF(string fileName, Stream source)
{
string fileNameNoExt = Path.GetFileNameWithoutExtension(fileName);
string fileExt = Path.GetExtension(fileName);
string filestreamPath;
byte[] filestreamTxn;
string connStr = ConfigurationManager.ConnectionStrings["archiveDbConnectionString"].ConnectionString;
using (TransactionScope ts = new TransactionScope())
{
using (SqlConnection conn = new SqlConnection(connStr))
{
conn.Open();
#region uspUploadAnalystReport
SqlCommand cmd1 = conn.CreateCommand();
cmd1.CommandType = CommandType.StoredProcedure;
cmd1.CommandText = "uspUploadAnalystReport";
SqlParameter cmd1Param1 = cmd1.Parameters.Add("@filename", SqlDbType.NVarChar);
cmd1Param1.Value = fileNameNoExt;
SqlParameter cmd1Param2 = cmd1.Parameters.Add("@ext", SqlDbType.NVarChar);
cmd1Param2.Value = fileExt;
using (SqlDataReader rdr = cmd1.ExecuteReader(CommandBehavior.SingleRow))
{
rdr.Read();
filestreamPath = rdr.GetSqlString(0).Value;
filestreamTxn = rdr.GetSqlBinary(1).Value;
rdr.Close();
}
#endregion
#region save file content
const int BlockSize = 1024 * 512;
try
{
using (SqlFileStream dest = new SqlFileStream(filestreamPath, filestreamTxn, FileAccess.Write))
{
byte[] buffer = new byte[BlockSize];
int bytesRead;
while ((bytesRead = source.Read(buffer, 0, buffer.Length)) > 0)
{
dest.Write(buffer, 0, bytesRead);
dest.Flush();
}
dest.Close();
}
}
finally
{
source.Close();
}
#endregion
}
ts.Complete();
}
}
The pathName parameter of the first C# method is obtained by file_stream.PathName() in T-SQL.
Below is the stored procedure being called by the second C# method:
CREATE PROCEDURE uspUploadAnalystReport
@filename nvarchar(150),
@ext nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @name nvarchar(255) = @filename + @ext
IF @@TRANCOUNT = 0
BEGIN
THROW 51000, 'Stored Proc must be called within a transaction.', 1;
END
DECLARE @inserted TABLE (path_name nvarchar(max), filestreamTxn varbinary(max), path_locator_str nvarchar(4000))
DECLARE @i int = 0
WHILE 1 = 1
BEGIN
IF EXISTS (SELECT 1 FROM AnalystReports WHERE name = @name)
BEGIN
SET @i += 1;
SET @name = @filename + '_' + CAST(@i AS varchar(50)) + @ext
END
ELSE
BEGIN
BREAK;
END
END
INSERT AnalystReports (name, file_stream)
OUTPUT
inserted.file_stream.PathName(),
GET_FILESTREAM_TRANSACTION_CONTEXT(),
CAST(inserted.path_locator AS nvarchar(4000)) INTO @inserted
VALUES (@name, (0x));
SELECT * FROM @inserted;
END
public static byte[] ReadAnalystReportPDF(string pathName)
{
byte[] buffer = new byte[0];
if (CommonUtil.IsEmpty(pathName)) return buffer;
string connStr = ConfigurationManager.ConnectionStrings["archiveDbConnectionString"].ConnectionString;
using (SqlConnection conn = new SqlConnection(connStr))
{
conn.Open();
SqlTransaction transaction = conn.BeginTransaction();
SqlCommand cmd = conn.CreateCommand();
cmd.Transaction = transaction;
cmd.CommandText = "SELECT GET_FILESTREAM_TRANSACTION_CONTEXT()";
Object obj = cmd.ExecuteScalar();
byte[] txContext = (byte[])obj;
SqlFileStream fileStream = new SqlFileStream(pathName, txContext, FileAccess.Read);
buffer = new byte[(int)fileStream.Length];
fileStream.Read(buffer, 0, buffer.Length);
fileStream.Close();
cmd.Transaction.Commit();
}
return buffer;
}
public static void UploadAnalystReportPDF(string fileName, Stream source)
{
string fileNameNoExt = Path.GetFileNameWithoutExtension(fileName);
string fileExt = Path.GetExtension(fileName);
string filestreamPath;
byte[] filestreamTxn;
string connStr = ConfigurationManager.ConnectionStrings["archiveDbConnectionString"].ConnectionString;
using (TransactionScope ts = new TransactionScope())
{
using (SqlConnection conn = new SqlConnection(connStr))
{
conn.Open();
#region uspUploadAnalystReport
SqlCommand cmd1 = conn.CreateCommand();
cmd1.CommandType = CommandType.StoredProcedure;
cmd1.CommandText = "uspUploadAnalystReport";
SqlParameter cmd1Param1 = cmd1.Parameters.Add("@filename", SqlDbType.NVarChar);
cmd1Param1.Value = fileNameNoExt;
SqlParameter cmd1Param2 = cmd1.Parameters.Add("@ext", SqlDbType.NVarChar);
cmd1Param2.Value = fileExt;
using (SqlDataReader rdr = cmd1.ExecuteReader(CommandBehavior.SingleRow))
{
rdr.Read();
filestreamPath = rdr.GetSqlString(0).Value;
filestreamTxn = rdr.GetSqlBinary(1).Value;
rdr.Close();
}
#endregion
#region save file content
const int BlockSize = 1024 * 512;
try
{
using (SqlFileStream dest = new SqlFileStream(filestreamPath, filestreamTxn, FileAccess.Write))
{
byte[] buffer = new byte[BlockSize];
int bytesRead;
while ((bytesRead = source.Read(buffer, 0, buffer.Length)) > 0)
{
dest.Write(buffer, 0, bytesRead);
dest.Flush();
}
dest.Close();
}
}
finally
{
source.Close();
}
#endregion
}
ts.Complete();
}
}
The pathName parameter of the first C# method is obtained by file_stream.PathName() in T-SQL.
Below is the stored procedure being called by the second C# method:
CREATE PROCEDURE uspUploadAnalystReport
@filename nvarchar(150),
@ext nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @name nvarchar(255) = @filename + @ext
IF @@TRANCOUNT = 0
BEGIN
THROW 51000, 'Stored Proc must be called within a transaction.', 1;
END
DECLARE @inserted TABLE (path_name nvarchar(max), filestreamTxn varbinary(max), path_locator_str nvarchar(4000))
DECLARE @i int = 0
WHILE 1 = 1
BEGIN
IF EXISTS (SELECT 1 FROM AnalystReports WHERE name = @name)
BEGIN
SET @i += 1;
SET @name = @filename + '_' + CAST(@i AS varchar(50)) + @ext
END
ELSE
BEGIN
BREAK;
END
END
INSERT AnalystReports (name, file_stream)
OUTPUT
inserted.file_stream.PathName(),
GET_FILESTREAM_TRANSACTION_CONTEXT(),
CAST(inserted.path_locator AS nvarchar(4000)) INTO @inserted
VALUES (@name, (0x));
SELECT * FROM @inserted;
END
2014-03-11
New THROW statement in SQL Server 2012 (vs RAISERROR)
The new THROW keyword introduced in SQL server 2012 is an improvement over the existing RAISERROR() statement.
Both RAISERROR & THROW can be used in T-SQL code/script to raise and throw error within a TRY-CATCH block.
With RAISERROR developers had to use different ERROR_XXX() system functions to get the error details to pass through the RAISERROR() statement, like:
- ERROR_NUMBER()
- ERROR_MESSAGE()
- ERROR_SEVERITY()
- ERROR_STATE()
let’s see an example:
-- Using RAISERROR()
DECLARE
@ERR_MSG AS NVARCHAR(4000)
,@ERR_SEV AS SMALLINT
,@ERR_STA AS SMALLINT
BEGIN TRY
SELECT 1/0 as DivideByZero
END TRY
BEGIN CATCH
SELECT @ERR_MSG = ERROR_MESSAGE(),
@ERR_SEV =ERROR_SEVERITY(),
@ERR_STA = ERROR_STATE()
SET @ERR_MSG= 'Error occurred while retrieving the data from database: ' + @ERR_MSG
RAISERROR (@ERR_MSG, @ERR_SEV, @ERR_STA) WITH NOWAIT
END CATCH
GO
Output:
(0 row(s) affected)
Msg 50000, Level 16, State 1, Line 15
Error occurred while retrieving the data from database: Divide by zero error encountered.
The RAISERROR() can take first argument as message_id also instead of the message. But if you want to pass the message_id then it has to be in sys.messages
With THROW the benefit is: it is not mandatory to pass any parameter to raise an exception. Just using the THROW; statement will get the error details and raise it, as shown below:
-- Using THROW - 1
BEGIN TRY
SELECT 1/0 as DivideByZero
END TRY
BEGIN CATCH
THROW;
END CATCH
GO
Output:
(0 row(s) affected)
Msg 8134, Level 16, State 1, Line 2
Divide by zero error encountered.
As you see in the Output above, the error message thrown is the default one. But you can also add your customized message, we will see below.
IMP NOTE: Default THROW statement will show the exact line where the exception was occurred, here the line number is 2. But RAISERROR() will show the line number where the RAISERROR statement was executed i.e. Line 15 and not the actual exception.
Also passing the message_id won’t require it to be stored in sys.messages, let’s check this:
-- Using THROW - 2
DECLARE
@ERR_MSG AS NVARCHAR(4000)
,@ERR_STA AS SMALLINT
BEGIN TRY
SELECT 1/0 as DivideByZero
END TRY
BEGIN CATCH
SELECT @ERR_MSG = ERROR_MESSAGE(),
@ERR_STA = ERROR_STATE()
SET @ERR_MSG= 'Error occurred while retrieving the data from database: ' + @ERR_MSG;
THROW 50001, @ERR_MSG, @ERR_STA;
END CATCH
GO
Output:
(0 row(s) affected)
Msg 50001, Level 16, State 1, Line 14
Error occurred while retrieving the data from database: Divide by zero error encountered.
But if you parameterize the THROW statement as above it will not show the actual position of exception occurrence, and the behavior will be same as RAISERROR(). As with RAISERROR() you've to provide mandatory params, so there is no way to get the actual position of Line where the error occurred.
Both RAISERROR & THROW can be used in T-SQL code/script to raise and throw error within a TRY-CATCH block.
With RAISERROR developers had to use different ERROR_XXX() system functions to get the error details to pass through the RAISERROR() statement, like:
- ERROR_NUMBER()
- ERROR_MESSAGE()
- ERROR_SEVERITY()
- ERROR_STATE()
let’s see an example:
-- Using RAISERROR()
DECLARE
@ERR_MSG AS NVARCHAR(4000)
,@ERR_SEV AS SMALLINT
,@ERR_STA AS SMALLINT
BEGIN TRY
SELECT 1/0 as DivideByZero
END TRY
BEGIN CATCH
SELECT @ERR_MSG = ERROR_MESSAGE(),
@ERR_SEV =ERROR_SEVERITY(),
@ERR_STA = ERROR_STATE()
SET @ERR_MSG= 'Error occurred while retrieving the data from database: ' + @ERR_MSG
RAISERROR (@ERR_MSG, @ERR_SEV, @ERR_STA) WITH NOWAIT
END CATCH
GO
Output:
(0 row(s) affected)
Msg 50000, Level 16, State 1, Line 15
Error occurred while retrieving the data from database: Divide by zero error encountered.
The RAISERROR() can take first argument as message_id also instead of the message. But if you want to pass the message_id then it has to be in sys.messages
With THROW the benefit is: it is not mandatory to pass any parameter to raise an exception. Just using the THROW; statement will get the error details and raise it, as shown below:
-- Using THROW - 1
BEGIN TRY
SELECT 1/0 as DivideByZero
END TRY
BEGIN CATCH
THROW;
END CATCH
GO
Output:
(0 row(s) affected)
Msg 8134, Level 16, State 1, Line 2
Divide by zero error encountered.
As you see in the Output above, the error message thrown is the default one. But you can also add your customized message, we will see below.
IMP NOTE: Default THROW statement will show the exact line where the exception was occurred, here the line number is 2. But RAISERROR() will show the line number where the RAISERROR statement was executed i.e. Line 15 and not the actual exception.
Also passing the message_id won’t require it to be stored in sys.messages, let’s check this:
-- Using THROW - 2
DECLARE
@ERR_MSG AS NVARCHAR(4000)
,@ERR_STA AS SMALLINT
BEGIN TRY
SELECT 1/0 as DivideByZero
END TRY
BEGIN CATCH
SELECT @ERR_MSG = ERROR_MESSAGE(),
@ERR_STA = ERROR_STATE()
SET @ERR_MSG= 'Error occurred while retrieving the data from database: ' + @ERR_MSG;
THROW 50001, @ERR_MSG, @ERR_STA;
END CATCH
GO
Output:
(0 row(s) affected)
Msg 50001, Level 16, State 1, Line 14
Error occurred while retrieving the data from database: Divide by zero error encountered.
But if you parameterize the THROW statement as above it will not show the actual position of exception occurrence, and the behavior will be same as RAISERROR(). As with RAISERROR() you've to provide mandatory params, so there is no way to get the actual position of Line where the error occurred.
2014-03-05
Update View Definition After Underlying Table Changed
One of the tasks that a SQL Server DBA/developer mostly miss out is to update the definition of all the dependent views after an underlying table changed its schema (add/drop/modify a column). Unlike the recompilation of stored procedures, SQL Server will NOT automatically refresh the definition of views in case of table schema change, you must do it manually by running the sp_refreshview system stored procedure.
But why it's easily missed out by so many DBA? Because 1) no error will be raised when you alter the table (except you have SCHEMABINDING view); 2) if the SQL developer follows a good coding practice - avoid using "SELECT * FROM...", when writing any SQL objects, including views, then even the view definition is outdated, mostly the view performs exactly the same as before (I just can say mostly, because SQL Server keeps changed its internal mechanism, and there are too much variations of your coding in the real world).
Below is an example shows why you need to run sp_refreshview explicitly:
-- Create sample table for SQL view object
Create Table ViewTable (
id int identity(1,1),
viewname sysname,
description nvarchar(max),
active bit
)
go
-- Insert sample data into SQL table
insert into ViewTable select 'SQLView1','Sample SQL View',1
insert into ViewTable select 'SQLView2','Example T-SQL View',1
go
-- Create Transact-SQL View in SQL Server
Create View ViewTableList
as
select * from ViewTable
go
SELECT * FROM ViewTable -- read data from database table
SELECT * FROM ViewTableList -- read data from SQL view object
Alter Table ViewTable Add CreateDate datetime
go
SELECT * FROM ViewTable -- Select data directly from database table
SELECT * FROM ViewTableList -- Select data from non-updated view
Execute sp_refreshview 'ViewTableList' -- refresh view definition in SQL Server
SELECT * FROM ViewTable -- Select data directly from database table
SELECT * FROM ViewTableList -- Select data from updated view
Anyway, do it manually can prevent any uncertainties. Keep this step as one of your DBA practices.
But why it's easily missed out by so many DBA? Because 1) no error will be raised when you alter the table (except you have SCHEMABINDING view); 2) if the SQL developer follows a good coding practice - avoid using "SELECT * FROM...", when writing any SQL objects, including views, then even the view definition is outdated, mostly the view performs exactly the same as before (I just can say mostly, because SQL Server keeps changed its internal mechanism, and there are too much variations of your coding in the real world).
Below is an example shows why you need to run sp_refreshview explicitly:
-- Create sample table for SQL view object
Create Table ViewTable (
id int identity(1,1),
viewname sysname,
description nvarchar(max),
active bit
)
go
-- Insert sample data into SQL table
insert into ViewTable select 'SQLView1','Sample SQL View',1
insert into ViewTable select 'SQLView2','Example T-SQL View',1
go
-- Create Transact-SQL View in SQL Server
Create View ViewTableList
as
select * from ViewTable
go
SELECT * FROM ViewTable -- read data from database table
SELECT * FROM ViewTableList -- read data from SQL view object
Alter Table ViewTable Add CreateDate datetime
go
SELECT * FROM ViewTable -- Select data directly from database table
SELECT * FROM ViewTableList -- Select data from non-updated view
Execute sp_refreshview 'ViewTableList' -- refresh view definition in SQL Server
SELECT * FROM ViewTable -- Select data directly from database table
SELECT * FROM ViewTableList -- Select data from updated view
Anyway, do it manually can prevent any uncertainties. Keep this step as one of your DBA practices.
Subscribe to:
Comments (Atom)